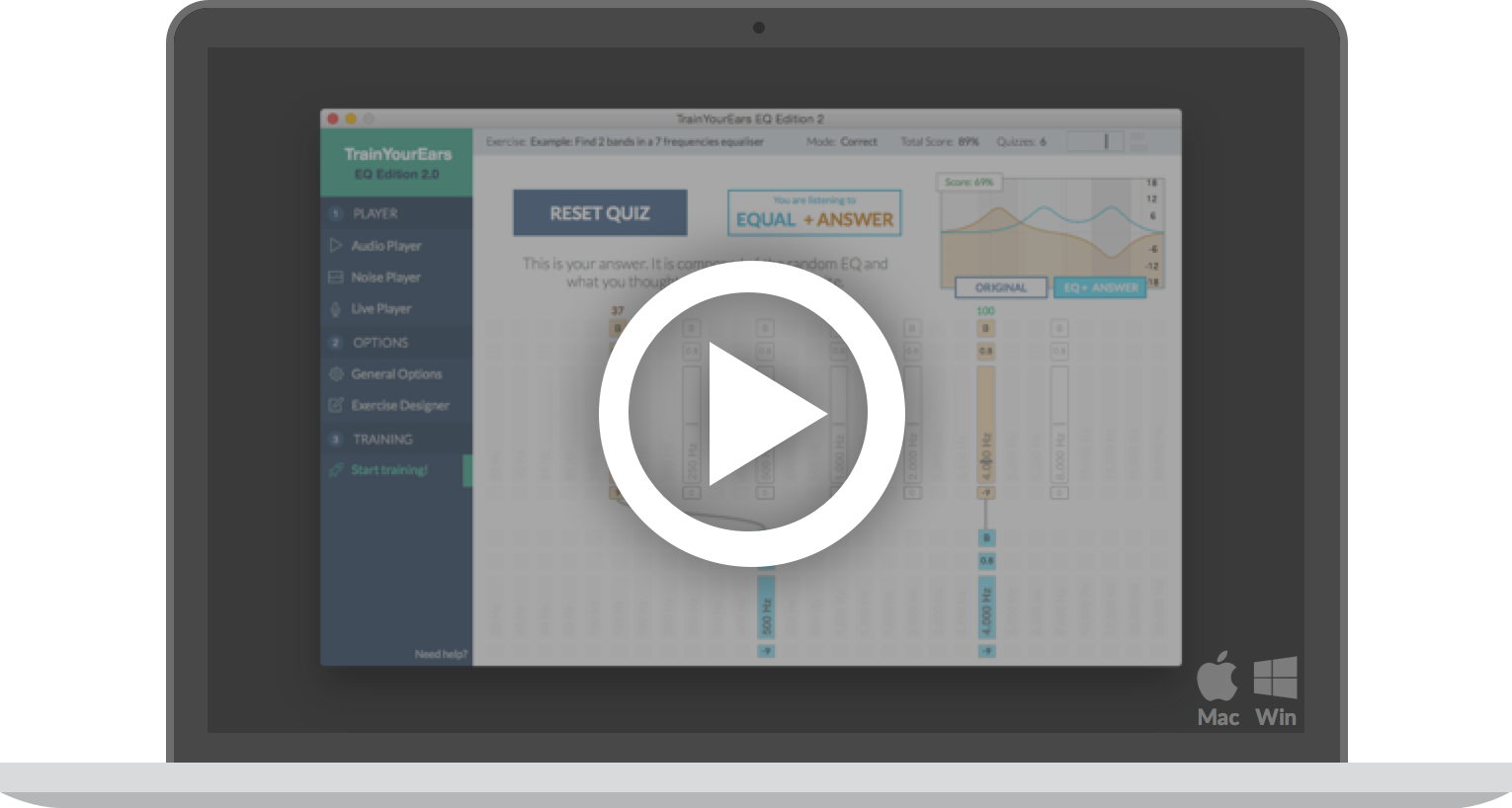
TrainYourEars EQ Edition is an ear training software for Mac and PC designed to help you understand equalisers and frequencies like never before.

It speeds up your learning process exposing you to hundreds of random equalizations you have to guess. If you are wrong, it will let you know “how wrong”, and it will let you hear both your guess and the correct answer.
In no time you will develop a frequency memory which will allow you to connect the sound you imagine in your head with the parameters you need to dial, quickly and easily than ever.

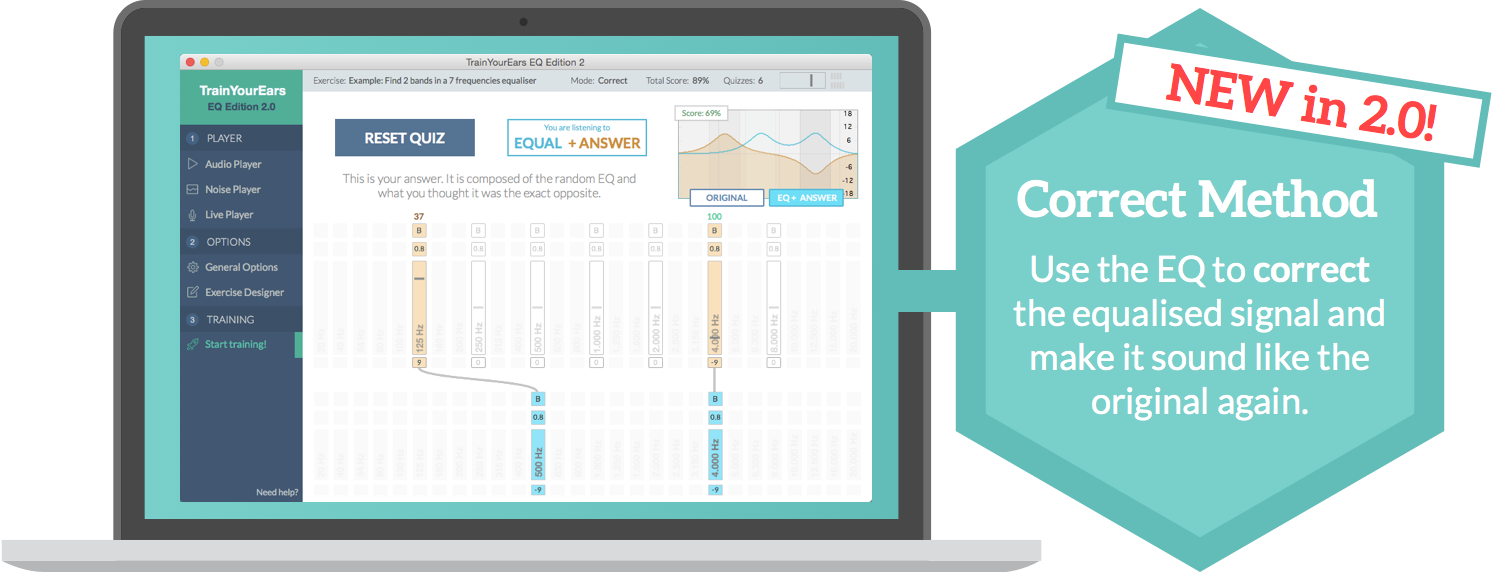
It has a brand new training method. Instead of guessing, you have to make corrections while you hear the result.
The person who suggested this method to us in the first place was Bob Katz, a renowned mastering guru. We tested it, we loved it, so here it is for all you to enjoy!
Besides it has a new, modern and clean interface, a new assisted training screen, a new exercise designer, it supports other languages, and many other features.
The ability to connect what is in your mind with the appropriate parameters you have to dial to get that sound is not an easy task. The steps involved should be:
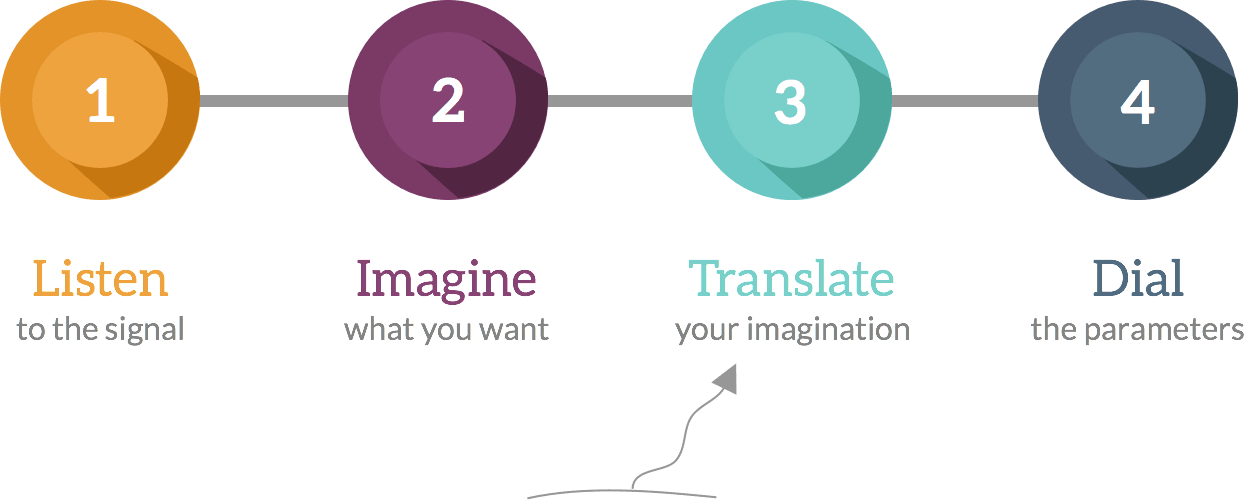
Sometimes people get lost in the translation step and start turning knobs without confidence. The more you work, the better you understand what those knobs really do, but it is a slow process.
People excel in this matter after many years, because they have learned experimenting with lots of different processes applied to lots of different sources. The purpose of this training is to open your ears to what each frequency sounds like and reduce the amount of time needed to acquire this knowledge.
In 15 minutes you can guess or correct 100 random equalisations, so training every day for a few weeks is equivalent to accumulating the experience of many years.
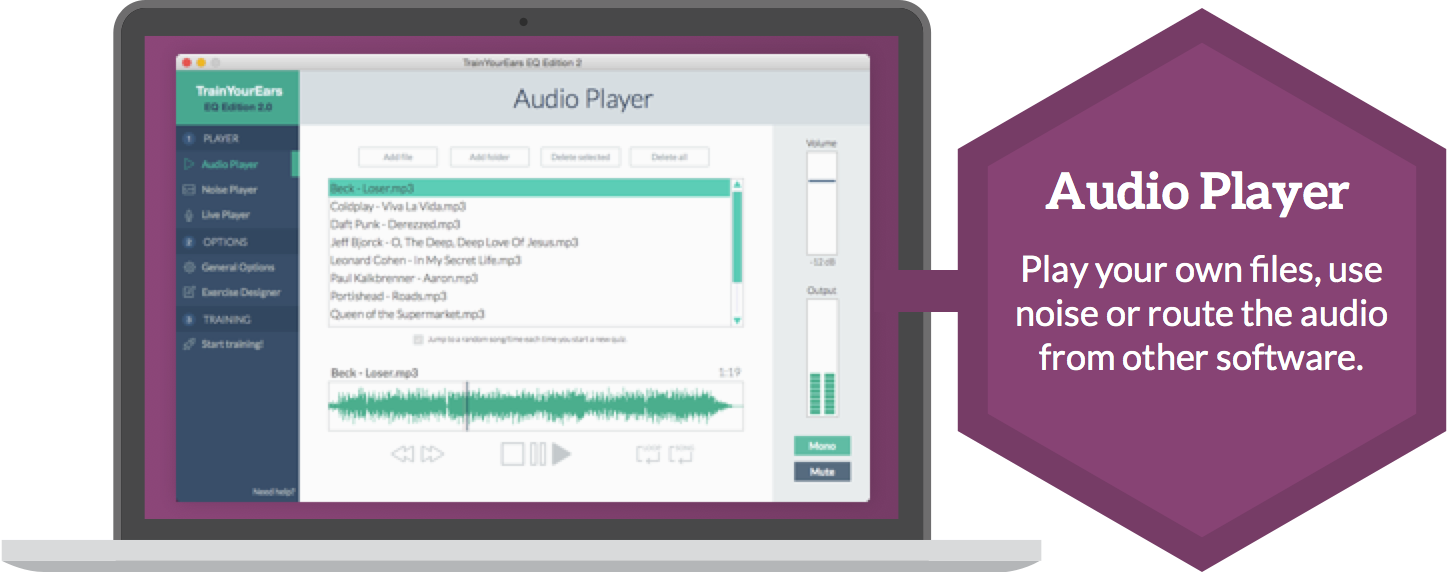
First, you load the music you want to train with:
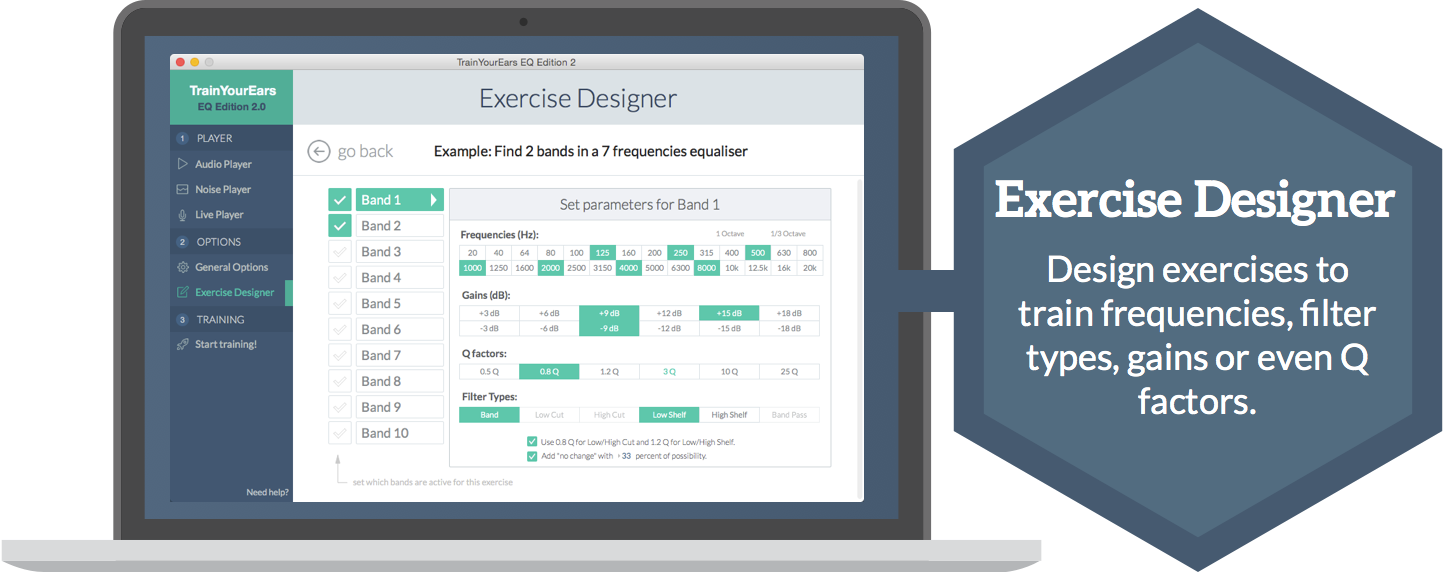
Then, you choose an exercise or design a new one:
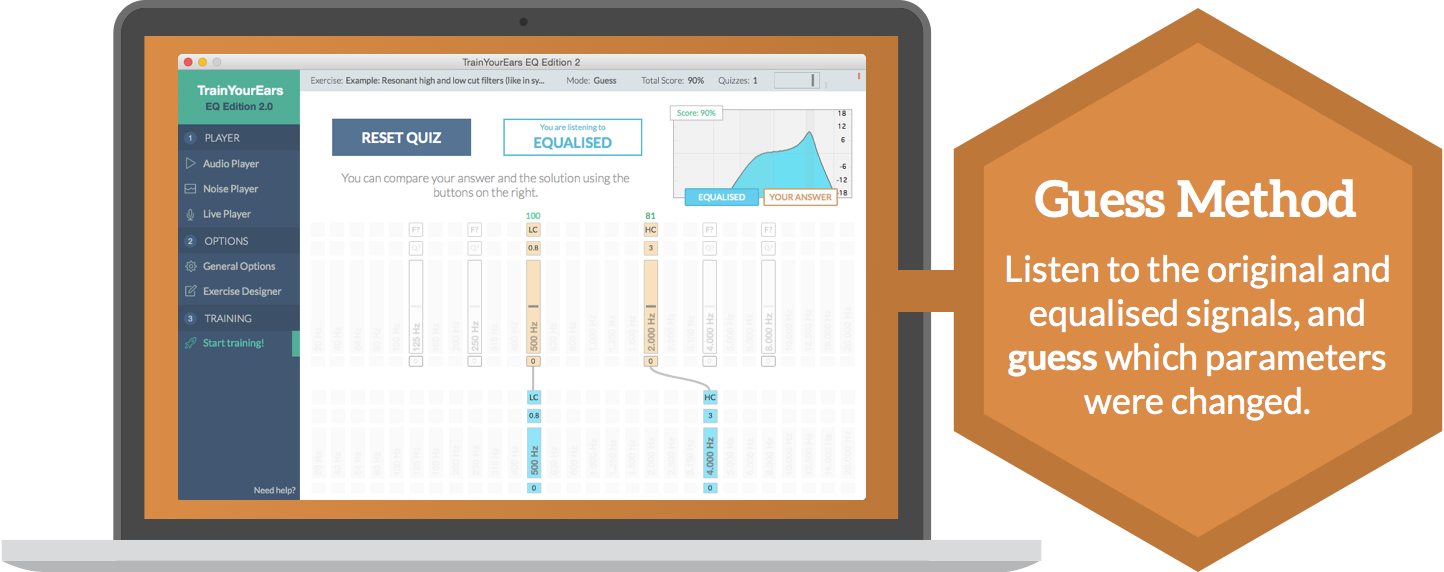
And finally, train your ears with one of these two methods!
Wanna see more?
Mira never deleted START-220.mp4. Instead, she added a note to its description: “When you’re lost, don’t search harder. Start here.”
She rewrote the aggregation logic in two hours. The pipeline ran overnight. By morning, it worked.
In a quiet server room deep within the NeuroSync Research Lab, a single file sat untouched for years: . Most of the team assumed it was corrupted—just a broken placeholder from an old project. But junior analyst Mira Patel was curious.
One rainy Tuesday, she pulled up the file’s metadata. No thumbnail. No duration. Just a timestamp from five years ago and a single tag: “Help begins here.”
Years later, when she became team lead, she saw new analysts discover the file. Some laughed. Some tried the ritual. Almost all of them, at some quiet moment, whispered thanks to a video that taught them:
Mira double-clicked.
“The recommendation engine keeps collapsing on sparse user histories,” she said aloud. Then she walked to the break room, stared out the window at the rain, and returned. On the whiteboard, she drew users as small circles, items as squares, and sparse connections as dotted lines. Halfway through, she saw it: the dotted lines weren’t missing data—they were clusters waiting to be grouped differently .
Mira never deleted START-220.mp4. Instead, she added a note to its description: “When you’re lost, don’t search harder. Start here.”
She rewrote the aggregation logic in two hours. The pipeline ran overnight. By morning, it worked. START-220.mp4
In a quiet server room deep within the NeuroSync Research Lab, a single file sat untouched for years: . Most of the team assumed it was corrupted—just a broken placeholder from an old project. But junior analyst Mira Patel was curious. Mira never deleted START-220
One rainy Tuesday, she pulled up the file’s metadata. No thumbnail. No duration. Just a timestamp from five years ago and a single tag: “Help begins here.” The pipeline ran overnight
Years later, when she became team lead, she saw new analysts discover the file. Some laughed. Some tried the ritual. Almost all of them, at some quiet moment, whispered thanks to a video that taught them:
Mira double-clicked.
“The recommendation engine keeps collapsing on sparse user histories,” she said aloud. Then she walked to the break room, stared out the window at the rain, and returned. On the whiteboard, she drew users as small circles, items as squares, and sparse connections as dotted lines. Halfway through, she saw it: the dotted lines weren’t missing data—they were clusters waiting to be grouped differently .
Final price was 89€, but the 49€ launch offer was such a success that we sold twice as many as we expected.
After a lot of thought we decided to keep this reduced price forever :)
Thanks to all the people who has supported this project so far and made this possible!




Trusted by thousands of students and teachers from the world’s top universities.